VAMboozled!: NCTQ on States’ Teacher Evaluation Systems’ Failures
The controversial National Council on Teacher Quality (NCTQ) — created by the conservative Thomas B. Fordham Institute and funded (in part) by the Bill & Melinda Gates Foundation as “part of a coalition for ‘a better orchestrated agenda’ for accountability, choice, and using test scores to drive the evaluation of teachers” (see here; see also other instances of controversy here and here) — recently issued yet another report about state’s teacher evaluation systems titled: “Running in Place: How New Teacher Evaluations Fail to Live Up to Promises.” See a related blog post in Education Week about this report here. See also a related blog post about NCTQ’s prior large-scale (and also slanted) study — “State of the States 2015: Evaluating Teaching, Leading and Learning” — here. Like I did in that post, I summarize this study below.
From the abstract: Authors of this report find that “within the 30 states that [still] require student learning measures to be at least a significant factor in teacher evaluations, state guidance and rules in most states allow teachers to be rated effective even if they receive low scores on the student learning component of the evaluation.” They add in the full report that in many states “a high score on an evaluation’s observation and [other] non-student growth components [can] result in a teacher earning near or at the minimum number of points needed to earn an effective rating. As a result, a low score on the student growth component of the evaluation is sufficient in several states to push a teacher over the minimum number of points needed to earn a summative effective rating. This essentially diminishes any real influence the student growth component has on the summative evaluation rating” (p. 3-4).
The first assumption surrounding the authors’ main tenets they make explicit: that “[u]nfortunately, [the] policy transformation [that began with the publication of the “Widget Effect” report in 2009] has not resulted in drastic alterations in outcomes” (p. 2). This is because, “[in] effect…states have been running in place” (p. 2) and not using teachers’ primarily test-based indicators for high-stakes decision-making. Hence, “evaluation results continue to look much like they did…back in 2009” (p. 2). The authors then, albeit ahistorically, ask, “How could so much effort to change state laws result in so little actual change?” (p. 2). Yet they don’t realize (or care to realize) that this is because we have almost 40 years of evidence that really any type of test-based, educational accountability policies and initiatives have never yield their intended consequences (i.e., increased student achievement on national and international indicators). Rather, the authors argue, that “most states’ evaluation laws fated these systems to status quo results long before” they really had a chance (p. 2).
The authors’ second assumption they imply: that the two most often used teacher evaluation indicators (i.e., the growth or value-added and observational measures) should be highly correlated, which many argue they should be IF in fact they are measuring general teacher effectiveness. But the more fundamental assumption here is that if the student learning (i.e., test based) indicators do not correlate with the observational indicators, the latter MUST be wrong, biased, distorted, and accordingly less trustworthy and the like. They add that “teachers and students are not well served when a teacher is rated effective or higher even though her [sic] students have not made sufficient gains in their learning over the course of a school year” (p. 4). Accordingly, they add that “evaluations should require that a teacher is rated well on both the student growth measures and the professional practice component (e.g., observations, student surveys, etc.) in order to be rated effective” (p. 4). Hence, also in this report the authors put forth recommendations for how states might address this challenge. See these recommendations forthcoming, as also related to a new phenomenon my students and I are studying called artificial inflation.
Artificial inflation is a term I recently coined to represent what is/was happening in Houston, and elsewhere (e.g., Tennessee), when district leaders (e.g., superintendents) mandate or force principals and other teacher effectiveness appraisers or evaluators to align their observational ratings of teachers’ effectiveness with teachers’ value-added scores, with the latter being (sometimes relentlessly) considered the “objective measure” around which all other measures (e.g., subjective observational measures) should revolve, or align. Hence, the push is to conflate the latter “subjective” measure to match the former “objective” measure, even if the process of artificial conflation causes both indicators to become invalid. As per my affidavit from the still ongoing lawsuit in Houston (see here), “[t]o purposefully and systematically endorse the engineering and distortion of the perceptible ‘subjective’ indicator, using the perceptibly ‘objective’ indicator as a keystone of truth and consequence, is more than arbitrary, capricious, and remiss…not to mention in violation of the educational measurement field’s “Standards for Educational and Psychological Testing.”
Nonetheless…
Here is one important figure, taken out of context in some ways on purpose (e.g., as the text surrounding this particular figure is ironically, subjectively used to define what the NCTQ defines as as indicators or progress, or regress).
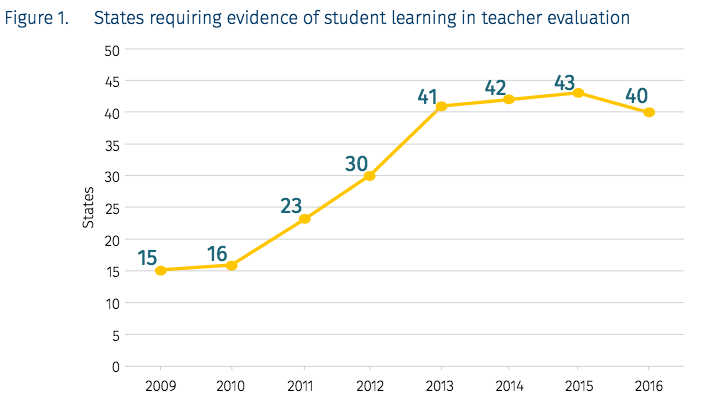
Near Figure 1 (p. 1) the authors note that “as of January 2017, there has been little evidence of a large-scale reversal of states’ formal evaluation policies. In fact, only four states (Alaska, Mississippi, North Carolina, and Oklahoma) have reversed course on factoring student learning into a teacher’s evaluation rating” (p. 3). While this reversal of four is not illustrated in their accompanying figure, see also a prior post about what other states, beyond just these four states of dishonorable mention, have done to “reverse” the “course” (p. 3) here. While the authors shame all states for minimizing teachers’ test-based ratings before these systems had a chance, as also ignorant to what they cite as “a robust body of research” (without references or citations here, and few elsewhere in a set of footnotes), they add that it remains an unknown as to “why state educational agencies put forth regulations or guidance that would allow teachers to be rated effective without meeting their student growth goals” (p. 4). Many of us know that this was often done to counter the unreliable and invalid results often yielded via the “objective” test-based sides of things that the NCTQ continues to advance.
Otherwise, here are also some important descriptive findings:
- Thirty states require measures of student academic growth to be at least a significant factor within teacher evaluations; another 10 states require some student growth, and 11 states do not require any objective measures of student growth (p. 5).
- With only [emphasis added] two exceptions, in the 30 states where student
growth is at least a significant factor in teacher evaluations, state
rules or guidance effectively allow teachers who have not met student
growth goals to still receive a summative rating of at least effective (p. 5). - In 18 [of these 30] states, state educational agency regulations and/or guidance
explicitly permit teachers to earn a summative rating of effective even after earning a less-than-effective score on the student learning portion of their evaluations…these regulations meet the letter of the law while still allowing teachers with low ratings on
student growth measures to be rated effective or higher (p. 5). In Colorado, for example…a teacher can earn a rating of highly effective with a score of just 1 for student growth (which the state classifies as “less than expected”) in conjunction with a top professional practice score (p. 4). - Ten states do not specifically address whether a teacher who has not met student growth goals may be rated as effective or higher. These states neither specifically allow nor specifically disallow such a scenario, but by failing to provide guidance to prevent such an occurrence, they enable it to exist (p. 6).
- Only two of the 30 states (Indiana and Kentucky) make it impossible for a teacher who has not been found effective at increasing student learning to receive a summative rating of effective (p. 6).
Finally, here are some of their important recommendations, as related to all of the above, and to create more meaningful teacher evaluation systems. So they argue, states should:
- Establish policies that preclude teachers from earning a label of effective if they are found ineffective at increasing student learning (p. 12).
- Track the results of discrete components within evaluation systems, both statewide and districtwide. In districts where student growth measures and observation measures are significantly out of alignment, states should reevaluate their systems and/or offer districts technical assistance (p. 12). ][That is, states should possibly promote artificial inflation as we have observed elsewhere. The authors add that] to ensure that evaluation ratings better reflect teacher performance, states should [more specifically] track the results of each evaluation measure to pinpoint where misalignment between components, such as between student learning and observation measures, exists. Where major components within an evaluation system are significantly misaligned, states should examine their systems and offer districts technical assistance where needed, whether through observation training or examining student growth models or calculations (p. 12-13). [Tennessee, for example,] publishes this information so that it is transparent and publicly available to guide actions by key stakeholders and point the way to needed reforms (p. 13).
See also state-by-state reports in the appendices of the full report, in case your state was one of the state’s that responded or, rather, “recognized the factual accuracy of this analysis.”
Citation: Walsh, K., Joseph, N., Lakis, K., & Lubell, S. (2017). Running in place: How new teacher evaluations fail to live up to promises. Washington DC: National Council on Teacher Quality (NCTQ). Retrieved from http://www.nctq.org/dmsView/Final_Evaluation_Paper
This blog post has been shared by permission from the author.
Readers wishing to comment on the content are encouraged to do so via the link to the original post.
Find the original post here:
The views expressed by the blogger are not necessarily those of NEPC.
