Jersey Jazzman: What are Tests Really Measuring? A Tale of Education "Reform" in Newark
This post is part of a series on recent research into Newark schools and education "reform."
Here's Part I.
"What is a test, and what does it really measure?"
I often get the sense that more than a few stakeholders and policy makers in education don't take a lot of time to think carefully about this question.
There aren't many people who would claim that a test score, by itself, is the ultimate product of education. And yet test scores dominate discussions of education policy: if your beloved program can show a gain in a test outcome, you're sure to cite that gain as evidence in favor of it.
That's what's been happening in Newark, New Jersey these days. As I said in my last post, new research was published by the Center for Education Policy Research at Harvard University this past fall that purportedly showed a gain in "value-added" on tests for Newark compared to the rest of the state. The researchers have attempted to make the case that a series of reforms, initiated by a $100 million grant from Mark Zuckerberg, prompted those gains. (A more technical study of their research, published by the National Bureau of Economic Research, is found here.)
To make their case, the CEPR researchers do what many others have done: take test scores from students, input them into a sophisticated statistical model, and compare the gains for various groups. To be clear, I do think using test scores this way is fine -- to a point.
Test outcomes can and often do contain useful information that, when properly used, tell us important things. But we always have to remember that a test is a sample of knowledge or ability at a particular point in time. Like all samples, test outcomes are subject to error. Give a child who ate a good breakfast and got enough sleep a test in a quiet room with the heat set properly, and you'll get one score. Give that same child the same test but on an empty stomach in a freezing cold room, and you'll almost certainly get something else.
The variation in outcomes here illustrates a critical point: Often the scores on a test vary because of factors that have nothing to do with what the test is trying to measure. Psychometricians will often talk about construct validity: the extent to which a test is measuring what it is supposed to be measuring. Making a valid test requires not only creating test items that vary based on what we're trying to measure; it also requires defining what we're trying to measure.
Take, for example, New Jersey's statewide assessments in Grades 3 through 8 -- assessments required by federal law. For a number of years, the state administrated the NJASK: the New Jersey Assessment of Skills and Knowledge. It was a paper-and-pencil test that assessed students in two domains: math and English language arts (ELA).
Those are very big domains. What, exactly, comes under ELA? Reading and writing, sure... but reading what? Fiction? Informational texts? Toward what end? Comprehension, sure... but what does that mean? How does anyone demonstrate they comprehend something? By summarizing the text, or by responding to it in an original way? Is there a fool-proof way to show comprehension? And at what level?
These questions aren't merely a philosophical exercise -- they matter when building a test. What goes into the construct we are trying to measure? And, importantly, do the tests we give vary based on what we intend to use the tests to measure?
In the case of the recent Newark research, the economists who conducted the study made an assumption: they believed the test scores they used vary based on the actions of school systems, which implement programs and policies of various kinds. They assumed that after applying their models -- models that attempt to strip away differences in student characteristics and abilities to learn -- the variation in outcomes can be attributed to things the Newark publicly-financed schools, including the charter schools, do that differ from schools in other parts of the state.
It's a big assumption. It requires showing that the policies and programs implemented can be documented and, if appropriate, measured. It requires showing that those policies and programs only took place in Newark. And it requires making the argument that the variation found in test outcomes came only from those policies and programs -- what social scientists would call the treatment.
Further, this assumption requires making yet another assumption:
In 2015, New Jersey switched its statewide exam from the NJASK to the PARCC: the Partnership for Assessment of Readiness for College and Careers. PARCC is (mostly) a computerized exam. Its supporters often claim it's a "better" exam, because, they say, it measures things that matter more. I'm not going to get into that debate now, but I will note that, so far as I know, no one ever conducted a validity study of the PARCC compared to the NJASK. In other words: we're not sure how the two tests differ in what they measure.
What I can say is that everyone agrees the two exams are different. From what I've seen and heard from others, the PARCC math exam relies more on language skills than the NJASK math exam did, requiring students to do more verbal problem solving (which would put non-native English speakers at a disadvantage). The PARCC ELA exam seems to put more emphasis on writing than the NJASK, although how that writing is graded remains problematic.
Keeping this in mind, let's look at this graph from the CEPR research (p.35):
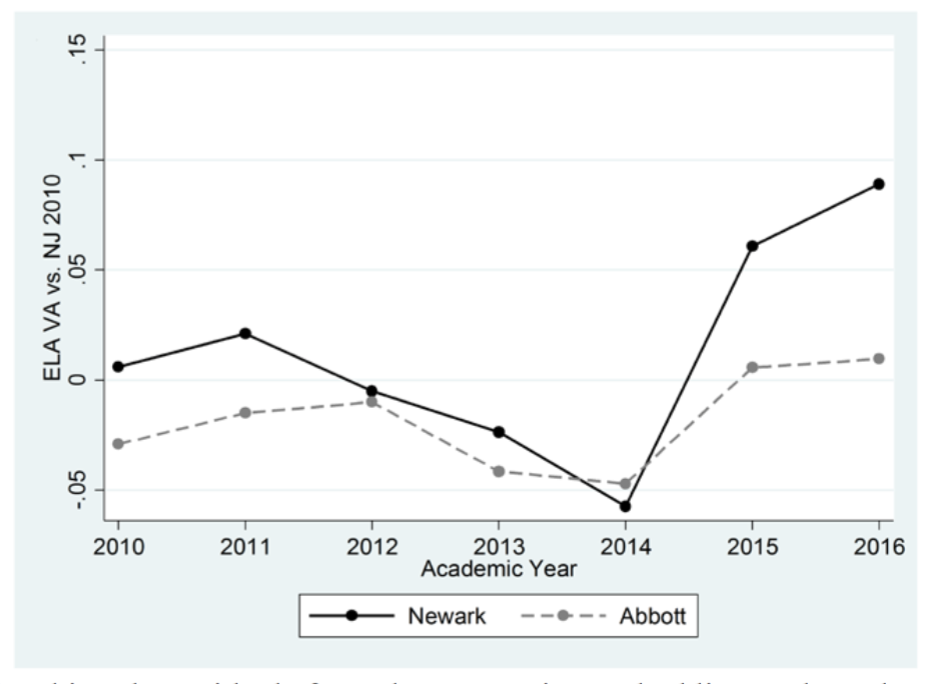
Until 2014, Newark's test score "growth" is pretty much the same as the other Abbott districts in the state. The Abbotts are a group of low-income districts that brought the famous Abbott v. Burke lawsuit, which forced the state toward more equitable school funding. They stand as a comparison group for Newark, because they have similar students and got similar test outcomes...
Until 2015. The Abbotts, as a group, saw gains compared to the rest of the state -- but Newark saw greater gains. Whether the size of those gains is educationally significant is something we'll talk about later; for right now, let's acknowledge they are statistically significant.
But why did they occur? Let me annotate this graph:
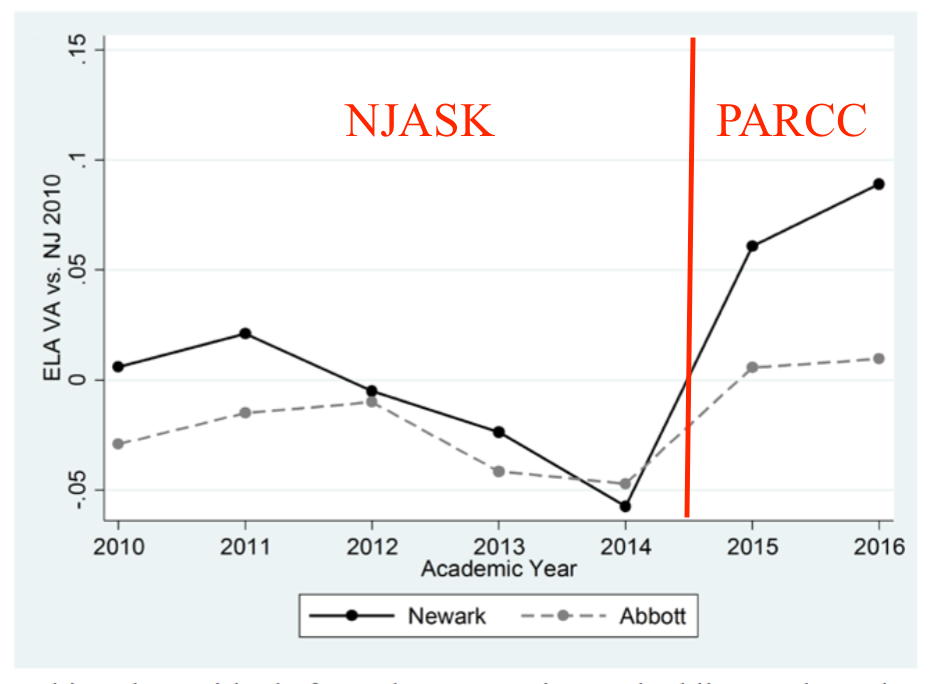
Newark's gains in "growth," relative to other, similar New Jersey districts, occurred in the same year the state switched exams.
And it's not just the CEPR research that shows this. As Bruce Baker and I showed in our review of that research, the state's own measure of growth, called Student Growth Percentiles (SGPs), also show a leap in achievement gains for Newark in the same year.

Again, the red line is the dividing point between the NJASK and the PARCC. In this case, however, we break down the districts into the Newark Public Schools, Newark's charter schools, and only those Abbotts in the same county as Newark. The districts close to Newark with similar demographics had similar gains in achievement "growth."
Let's step back and remember what the CEPR study was trying to understand: how a series of policies, initiated by Zuckerberg's donation, affected test score growth in Newark. What would we have to assume, based on this evidence, to believe that's true?
- That the Newark reforms, which began in 2011, didn't kick in until 2015, when they suddenly started affecting test scores.
- That the gains in the other Essex County Abbott districts (Irvington, Orange, and East Orange) were caused by some other factor completely separate from anything affecting Newark.
- That the switch from the NJASK to the PARCC didn't create any gains in growth that were unrelated to the construct the tests are purportedly measuring.
Test makers will sometimes refer to the concept of construct-irrelevant variation: that test outcomes will vary because things we do not want them to measure still affect the scores. If two children with equal mathematical ability take a computerized test, but one has greater facility in using a computer, their test scores will differ. The problem is that we don't want their scores to differ, because we're trying to measure math ability, not familiarity with computers.
Did Newark's students -- and Orange's and East Orange's and Irvington's -- do better on the PARCC simply because they felt more at ease with the new PARCC test than students around the rest of the state? Did these districts engage in test prep activities specific to the PARCC that brought scores up, but didn't necessarily reflect better instruction?
The CEPR study admits this is likely:
Assuming both tests have similar levels of measurement error, this implies that the PARCC and NJASK were assessing different sets of skills and the districts that excelled in preparing students for PARCC were not necessarily the same as the districts that excelled at preparing students for NJASK. Thus, what appears to be a single-year gain in performance may have been present before 2015, but was simply undetected by earlier NJASK tests. (p. 22, NBER, emphasis mine)
I'll get into that last sentence more in a future post. For now, it's enough to note this: Even the CEPR team acknowledges that the most likely explanation for Newark's gains is the state's switch from the NJASK to the PARCC. But aligning instruction with one test more than another is not the same as providing better instruction.
Gains like these are not necessarily an indication of curricular or instructional improvements. They are not necessarily brought about by moving students into "better" schools. They could very easily be the result of the tests measuring different things that we don't really want them to measure.
We'll talk more about this -- and get the views of a Harvard education expert -- next.
This blog post has been shared by permission from the author.
Readers wishing to comment on the content are encouraged to do so via the link to the original post.
Find the original post here:
The views expressed by the blogger are not necessarily those of NEPC.
