Code Acts in Education: The Birth of the Bio-Edu-Data-Sciences
This post is the script for a keynote lecture at the European Conference on Educational Research (ECER) at the University of Belgrade, Serbia, on 10 September 2025. It draws on material previously published in Postdigital Science and Education and a new article just out in the European Educational Research Journal.
In summer 2025, a startup technology company from Silicon Valley announced the launch of a genetic IQ test for embryos. Nucleus Genomics claimed its pre-implantation embryo testing platform was “the first genetic optimization software that lets parents see and understand a complete genetic profile to select an embryo.” The intelligence testing part of the platform is marketed as allowing prospective parents to select an embryo with high predicted IQ and the best chances of success in school – that is, of course, if you’re a wealthy parent with the dollars to spend on selecting a “superbaby”.
Now we could just respond to this by saying it’s modern eugenics and snake oil, as other critics have. This is clearly about promising the most privileged in our societies that they can improve their own gene pools, while profiting from scientifically misleading marketing. But my reason for starting with this example is because there has been a dramatic increase in interest over the last 10 to 15 years in how genetic data of this kind might be used in education. There is now ongoing discussion and debate about the potential of integrating genetic data, technologies and methods into educational practice and policy.
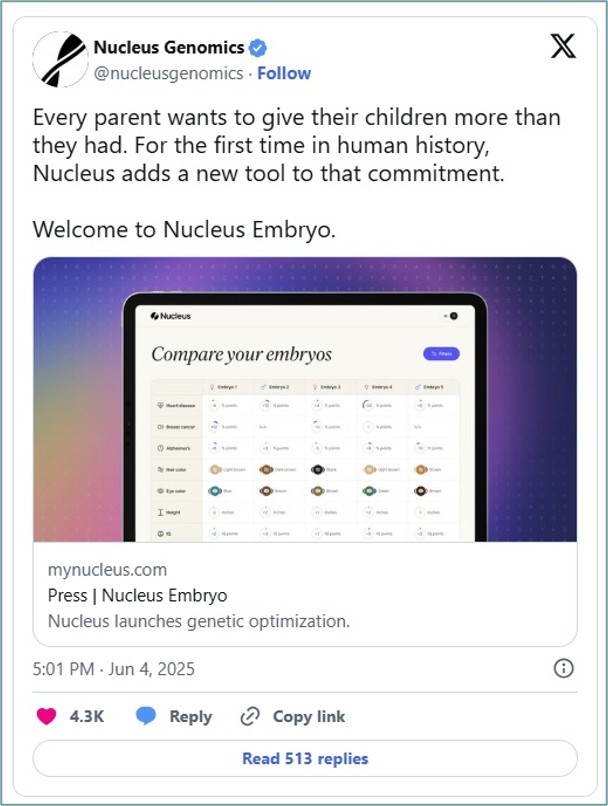
Image of a tweet from Nucleus Genomics announcing an embryo selection service
One reason for this interest is because new genomic technologies such as consumer DNA testing platforms – like the one from Nucleus – could be used to collect masses of genetic data about children. One expert adviser to Nucleus is a well-known behaviour geneticist who has written an entire book and a series of articles based on the idea of studying children’s DNA from consumer genetic testing. Several similar books and many academic papers all convene on one key idea – that genetic data, collected and analyzed with cutting-edge technologies, could transform our understanding of learning and educational outcomes, and could be used to design genetically-informed education systems and practices.
This is what we can characterize as the “geneticization of education”, “genomically informed education”, or “educational genomics”. Educational genomics aims, as scientists have claimed, to uncover the “underlying genetic architecture of academic achievement” and advance “a more comprehensive, biologically oriented model of individual differences in cognitive ability and learning”.
Educational genomics
Together with educational neuroscience, educational genomics represents the emergence of the “bio-edu-data sciences” – that is, highly data-intensive biological sciences of educationally relevant behaviours, processes and outcomes. The bio-edu-data sciences look into the body, brains and DNA, using advanced genomic and neurotechnologies to data-mine neural and genomic bioinformation. They are highly consequential – and controversial – for educational research, for policy and for practice.
I want to spend my time here today outlining the consequences and controversies associated with this biologization of education. I’m going to focus on educational genomics building on a project funded by the Leverhulme Trust and completed with my colleagues Dimitra Kotouza, Jessica Pykett, and Martyn Pickersgill.
Conceptually our project is grounded in social scientific studies of the biological sciences. Biology and especially human genetics have undergone a significant transformation in the couple of decades since the human genome was sequenced.
Researchers refer now to a “postgenomic condition” where “wet” biologically embodied substances and materials are no longer the main objects of biological investigation. Instead, biologists deal with “dry” digital “bioinformation” that is stored in databases and studied using bioinformatics software in computer labs. As Hallam Stevens phrases it, the computerization of biology has changed “what biologists do, how they work … what objects they deal with, and” – perhaps most importantly – “what kind of knowledge they produce”.
As biology has become increasingly “data-centric” as Sabina Leonelli argues, biological knowledge production has been reshaped by bioscientific technologies, databases and algorithms. How biologists think about biological objects has changed as they have become digital objects of scientific attention.
These bioinformational ways of doing and knowing biology have also been adopted into psychological and social scientific methods and practices, in the form of behavioural genetics and social science genomics. Behavioural genetics is a branch of psychology that traces complex human behaviours and traits to their underlying genetic base. Social science genomics tries to understand genetic influence on social and economic outcomes, tracking the pathways from “cells to society”.

Both behavioural and social genomics concentrate significant attention on education. They have adopted the genomic, data-centric style of bioinformatic investigation to discover the genetic bases of educational outcomes, achievements, and cognitive ability and intelligence. It’s a big shift in how research about educational matters is done, what data are collected, what methods are used, and what kind of knowledge is produced.
So, our conceptual orientation is to see educational genomics as an inventive science – it’s inventing a bioinformational account of learning and education. Educational genomics does not just make the biological substrates of learning outcomes visible at the molecular scale – it generates, fabricates, or invents them through the use of bioinformation or biodata. And it then promotes these bioinformational conceptualizations of learning as the basis for policy and practice in schools. Its objective is to make saliva samples from DNA swabs the basis for educational policy and classroom interventions.
Infrastructuring
The rest of the talk is framed around what I’m calling the 5 I’s of educational genomics – and those 5 I’s are infrastructuring, instrumenting, informatting, intervening and inventing.
Infrastructuring refers to the ongoing construction and maintenance of a complex system of scientific investigation and knowledge production. You can’t get from spit samples to social policy without this infrastructure. We’re drawing here on science and technology studies conceptualizations of “knowledge infrastructures” as relational systems of people, organizations, practices and technologies that underpin how scientific knowledge gets produced. Infrastructuring also highlights how objects of scientific investigation are bound up with large-scale computer-enabled information systems, which then mediate and shape how those objects are conceived, interpreted, and explained.
Educational genomics can only exist because a knowledge infrastructure for carrying out investigations and reporting findings has been constructed over the past 15 years. Educational genomics is not a “discipline” or a “field” but made up of a wide range of individuals, networks and associations. It is the infrastructure that holds them together and sustains their scientific investigations.
Central to this infrastructuring are databases of bioinformation. Databases perform a “harmonizing” function – which we mean in two ways. First, the collation of vast databases for analysis has involved the harmonization of diverse datasets. This harmonization function is a key aim of the Social Science Genetic Association Consortium. The SSGAC is the largest international network of scientists involved in social and behavioural genomics research. It produced the largest-sample studies of the genetic bases of educational outcomes – with genetic data on 3 million people.
The major sources of data are the UK Biobank, a publicly funded repository of genetic data from a British population sample, and 23andme, the Silicon Valley consumer genomics company with the planet’s largest private biobank, plus many smaller cohort datasets. A lot of harmonization is involved in making these datasets compatible for research, including legal, financial, logistical and technical practices and personnel.
Databases also facilitate the formation of harmonious scientific collectives, with shared aims, methods, theories and ways of working. As it says, the SSGAC is a “platform for interdisciplinary collaboration and cross-fertilization of ideas” and a repository of harmonized data.
In this sense, the knowledge infrastructure of educational genomics has been harmonized by databases. The scientists that enact educational genomics have been brought into harmonious relations in the form of interdisciplinary associations and networks that operate internationally and at scale to analyse very large datasets of bioinformation.
Instrumenting
Studying the bioinformation in those databases requires scientific instruments for analysis. These instruments are known as “bioinformatics” – the synthesis of biological science with the statistical, computer and data sciences.
Scientific instruments are, though, not simply “tools” that help scientists do their analyses. Instead, scientific instruments “actively mediate how reality becomes present to—and is treated by—scientists” as Bas de Boer and colleagues put it. The bioinformatic instruments used in contemporary biological research, “the quantities of data processed by computers, and the algorithms needed to deal with them, make a qualitatively different kind of knowledge,” as Hallam Stevens adds.
That has significant effects on how biological phenomena are seen and understood. Scientific instruments co-produce novel configurations of “biological reality”, leading to the production of “genomic facts” while excluding other ways of seeing and understanding biology.
The bioinformatic instruments of educational genomics include microarray chips. They’re little glass slides used to identify an individual’s genetic differences from the wider population or a sample represented in a specific dataset. What microarrays are said to surface are single nucleotide polymorphisms or SNPs – tiny molecular differences in DNA that, it is claimed, interact to influence complex behaviours, traits or outcomes.
The invention of these microarray instruments has enabled researchers doing educational genomics studies to claim that “molecular genetic research, particularly recent cutting-edge advances in DNA-based methods, has furthered our knowledge and understanding of cognitive ability, academic performance and their association”.
The 3 million sample study by the SSGAC, for example, claims to have identified the “genetic architecture” of educational attainment from microarrayed data. This genetic architecture consists of statistical associations between around 3000 interacting SNPs. This claim – that we know the molecular genetic architecture of learning outcomes – is why those doing educational genomics find microarrays so compelling. Some scientists have even called them “Learning Chips” and characterized microarrays as “DNA fortune tellers” that could predict educational outcomes in “genetically-sensitive” school systems.

Image of microarrays from Illumina
But the biological realism of these claims becomes more questionable if we recognize that these so-called Learning Chips are products of commercial biotechnology companies that have changed how biologists understand genetic variation. As Ramya Rajagopalan and Joan Fujimura put it, the design, statistical power, and technical constraints of the chips have shaped the “definition and significance of human genetic differences.” Microarrays have “locked in” the primary “conceptual frameworks humans should use to consider, organize, work with, and ultimately act on genetic differences”.
The association of molecular genetic variation with educational outcomes has therefore been “locked-in” to educational genomics by the design and constraints of DNA chips and the kinds of data analyses they enable. In this sense, instrumenting educational genomics with microarrays and other bioinformatic instruments doesn’t necessarily signify a more accurate, biologically realistic understanding of genetic differences and how they predict educational outcomes: the design of the instruments produces those differences, making them visible as bioinformational artefacts that stand as statistical proxies of biological mechanisms.
Informatting
The third of my 5Is of educational genomics is informatting, and it means two related things: first, the transformation of biology into information, and second the specific ways that bioinformation is formatted in standardized form.
Colin Koopman’s work on data formatting is key here. As he argues, “One thing that the genetic sciences do with tremendous success is to ‘format’ us as subjects of genetic data. In being formatted, rendered, or organized as genetic data, we come to be defined by that data. Others address us, deal with us, or even impose burdens and benefits on us in terms of the genetic data we have become.”
Koopman argues that data are formatted in three stages: as selected input data, as methods or formats for data storage and handling, and as formats of data sharing and presentation. How data are formatted at all three stages is consequential for how individuals and collectives are known genetically, and treated as a result.
The specific data format centred by educational genomics is called a “polygenic score”. A polygenic score is basically the sum total of the differences captured from one’s microarray data. So the microarray data are formatted by the design and constraints of the chip at the point of data input. Polygenic scores are then produced through specific methods, enacted by particular bioinformatics instruments, which render the data into a particular format – a single numerical score. That formatted score can then circulate as a seemingly genomic fact of one’s predicted educational achievements.
Now, in educational genomics, the most common polygenic scores are produced for educational attainment, described as “a phenotype affected by thousands of genetic variants, each responsible for a minuscule fraction of individual differences.” The task of the scientist is to add these up into a polygenic score that is said to be an authentic genetic signal of one’s educational attainment. That is a computationally intensive process of decoding complex genetic data into the simplified format of the score.
The SSGAC’s work is especially significant because the polygenic scores it derived from its large-sample studies are now the reference models used in other educational genomics studies – so the harmonized data and formatted scores are consequential in shaping the results of subsequent research.
We’ve termed this informatting because it’s a highly informationalized process, enacted with bioinformatics software and algorithms, that squeezes the biological correlates of learning into the format of the polygenic score. Scientists such as Cecile Janssens claim polygenic scores do not “exist” in the same way as other measurable or observable biological processes, but only as algorithms and simplified formats that create “a new biological reality”. How data are informatted then makes a considerable difference to how it can be presented, interpreted, and how ultimately it might be used for intervening in educational policy or practice.
Intervening
The informatting of complex data into simplified polygenic scores is consequential due to the plasticity of their possible application. Findings from polygenic scoring study get a lot of media attention about their potential uses in educational settings. We’ve identified four different ways that polygenic scores have been proposed for use in either education policy or practice interventions.
The first way polygenic scores have been proposed for use in education is through the idea of “precision education”, or the customization of pedagogy on the basis of a student’s personal polygenic score for educational achievement. As authors of a recent paper put it, “The DNA revolution has made it possible to predict individual differences in educational achievement from DNA … their use has been proposed for ‘predictive enrichment’ – that is identifying which populations are most likely to benefit from a given treatment.”
On this basis it has been claimed that “Polygenic scores are key for personalized learning, as they predict pupil’s profiles of strengths and weaknesses, which offers the possibility to intervene early to prevent problems and promote promise”.
But this seductive vision of “pinpointing children” for precisely-targeted pedagogic support also requires a particular kind of hierarchical arrangement based on measured genetic differences. As Callie Burt has phrased it, polygenic scores “are ‘rankings’ (i.e., positions on a scale) of genetic associations with socially valued outcomes”.
Polygenic scores used in this way are then a technology of ranking or ordinalization – you can plot students on to a genetic hierarchy. Precision education represents what we have called the “bioinformatic ordinalization” of students by polygenic scoring. This means ranking them on an ordinal scale of genetically predicted outcomes and targeting them for personalized intervention in the classroom.
The second proposed use of polygenic scores is as “screening tools” for group differentiation in schools. A 2021 report for the Early Intervention Foundation claimed that “It is increasingly possible to identify at birth children who have an elevated likelihood of outcomes such as struggling at school or being diagnosed with a learning, behaviour or mental health condition”. As the authors of a related research study elaborated, “Polygenic scores could be used as an additional tool for universal screening systems in authentic school settings, alongside the progress monitoring tools regularly used in schools, to differentiate based on group needs.”

Polygenic screening and differentiation emphasize the potential to group children into distinct clusters, identified by the shared distribution of SNPs associated with learning. We conceive these groupings as the designation of “polygenic biosocialities”.
The concept of biosociality refers, as Ian Hacking phrased it, to how an “avalanche of genetic information available about individuals and populations” has enabled the identification of groups according to genetic indicators associated with a biological condition. And as Paul Rabinow has argued, “Through the use of computers, individuals sharing certain traits or sets of traits can be grouped together” through a “technocratic administration of differences”.
Polygenic scoring here then means the production of polygenic biosocialities that are classified, sorted and differentiated by genomic screening technologies.
The third proposal for using polygenic scores is to support cost-savings and efficiencies. Polygenic scores here would operate as “bio-statistical indicators” of whether a policy is cost-effective and to indicate for whom, how and why it works. In the book The Genetic Lottery, for example, KP Harden proposes using genetic data to accelerate the search for effective, cost-saving interventions. She argues that interventions based on social sciences often “waste time and money” by “failing to even consider the role that genetics plays in how children’s lives turn out differently”.
These bio-statistical indicators would also produce knowledge for policymaking. As others have argued, “Not acknowledging genetically-informed explanations for individual differences in learning abilities and achievement can lead to sub-optimal policy decisions and sub-optimal experiences for children in schools.”
Here then we can understand polygenic scores as being wedded with the existing use of numbers and statistics in educational policy and governance. Polygenic scores become a source of governing knowledge for policy intervention design and as bio-statistical indicators for measuring policy effects.
The final promise of polygenic scores for policy is their potential to be used as the basis for economic prediction of “human capital”. We term this “geno-econometric biocapitalization”. Here the interdisciplinary field of “genoeconomics” is key: it combines economics and genomic sciences to make statistical predictions of the economic value associated with different distributions of DNA. Education is important to genoeconomists since it’s taken as a key indicator of later economic outcomes.
This “human capital” emphasis is evident in educational genomics papers, where it is claimed for instance that, for example, “Educational attainment is a measure of human capital and is indicative of the skills of a population. … Higher levels of educational attainment are associated with higher employment rates, better job prospects and higher earnings.”
Genoeconomics researchers therefore use polygenic scores as predictive econometric instruments to survey for biological signals of future human capital in the genome, and to call for social policy investments based on polygenic scores indicating human capital deficits. So, what we term the geno-econometric biocapitalization of children means the forecasting of future economic value from polygenic scores, foregrounding future human biocapital as the target of educational investments and interventions.
Inventing
So educational genomics is not only an expanding domain of research. It’s also an emerging source of authority in discussions over how genetic data could or should be used in educational interventions. My main point throughout has been that educational genomics needs to be understood as an inventive science. Its underpinning infrastructure and instruments don’t merely make the underlying biological substrates of learning outcomes visible, but fabricate or invent new genomic facts about learning as the result of molecular interactions amongst thousands of genetic polymorphisms.
As Mareile Kaufmann reminds us, “DNA does not speak for itself. It never did. Today, digital technologies are more than ever part of making DNA speak. DNA is collected and rendered into digital data by hardware. It is stored in a variety of databases and analyzed by algorithms. These techno-scientific dynamics matter…. Together, technologies, scientific procedure and human discretion co-produce how DNA speaks as information and what meaning it will have.”
Polygenic scores don’t speak for themselves either. They are bioinformatic inventions that also invent new biological accounts of learning and of what a student is. Through polygenic scoring, educational genomics has invented a de-substantialized, decoded, statistically calculable student body as a digital object of attention.
Educational genomics also reinvents ideas about schooling and education, posing new normative assertions that decisions about children’s schooling should be informed by genetic data – that teachers should take genetic bioinformation into account in their strategies of teaching and differentiation – that education should be about the cultivation of future human biocapital.
Invalidating
But these inventions also bring considerable social, political and ethical challenges. Let me finish up with some critical provocations that may invalidate many of the claims of educational genomics. My 6th I of educational genomics draws on recent critical accounts and controversies over polygenic scoring as a problematic methodology in education.

The first big issue is “non-portability”. The vast majority of genetic bioinformation used in these studies has been gathered from people classified as having white European ancestry. What is known genetically about learning outcomes is only relevant to that ancestry group and not portable to other populations. So if you introduced an intervention in schools based on insights from educational genomics, you would have to exclude other groups. Clearly there is a massive issue of reproducing and exacerbating racialized inequalities here that would invalidate many of the proposed interventions just described.
The second problem is “unknown biology”. Educational genomics is entirely a big data exercise, only reporting correlations between genetic variations and educational achievements. Actual mechanistic biological explanations are mostly absent in educational genomics. There is no causal explanation of how genetic polymorphisms actually affect outcomes, only algorithmically calculated correlational claims of their association.
The third is invalid claims of genomic salience. According to critics, social factors remain vastly more explanatory of educational outcomes than genetic predictors. The behaviour geneticist Eric Turkheimer argues recent scientific evidence actually shows that direct genetic effects on educational outcomes are near zero when you fully account for social factors. After 15 years of research, the genome might not, after all, tell us anything meaningful about the contribution of biology to educational outcomes and learning behaviours at all.
Conclusion
Educational genomics is evidence of the emergence of the bio-edu-data sciences as a source of growing authority in education. Bio-edu-data scientists are now seeking to data-mine the student body and brain with advanced technologies to sense out the molecular differences that it is argued make a difference in learning behaviours and outcomes. It’s important we keep engaging critically with the social and technical processes through which they are producing such knowledge claims and their assertions to objective biological knowledge and authority in education. Otherwise the genomic testing startups like Nucleus might stake their claim to educational authority and knowledge production too.
Educational genomics researchers are already claiming that “The rise in direct-to-consumer DNA testing suggests a future where genomically predicted achievement becomes more accessible. These companies are increasingly marketing their product to encourage parents to test their children … for educationally relevant traits.” There is now the prospect of such genomics startups becoming part of the knowledge infrastructure of the bio-edu-data sciences, and making the bioinformationally predictable student the object of policy attention and practice intervention.
The underpinning research for this talk can be found in:
Williamson, B, Kotouza, D, Pickersgill, M & Pykett, J (2024) Infrastructuring educational genomics: Associations, architectures, and apparatuses. Postdigital Science and Education 6: 1143–1172.
Williamson, B, Pykett, J & Kotouza, D (2026) Polygenic scores as bio-social policy instruments: Educational genomics as a source of intervention and governance. European Educational Research Journal, online first.
This blog post has been shared by permission from the author.
Readers wishing to comment on the content are encouraged to do so via the link to the original post.
Find the original post here:
The views expressed by the blogger are not necessarily those of NEPC.
